Spatial Transformer for 3D Point Clouds

Abstract
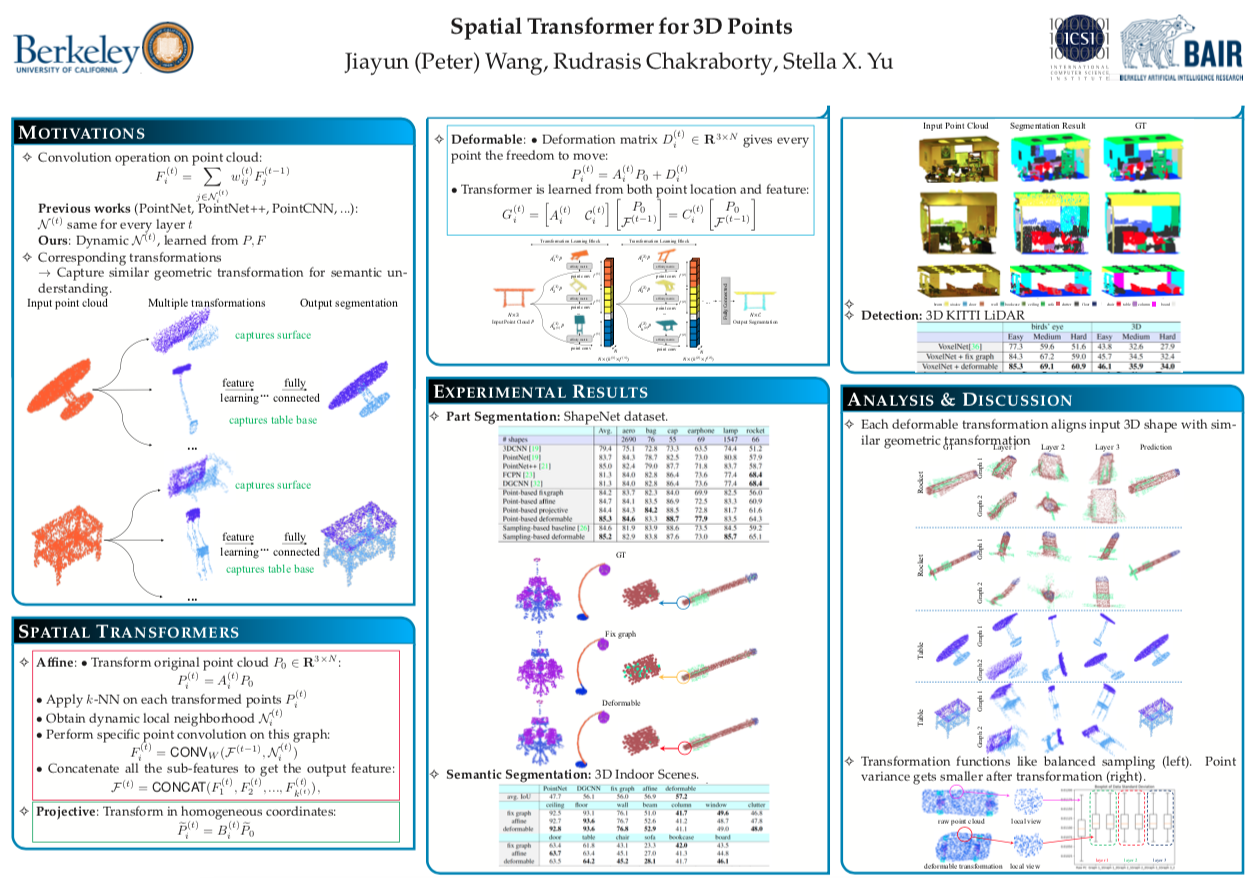
Deep neural networks can efficiently process 3D point clouds. At each point convolution layer, local features can be learned from local neighborhoods of the point cloud. These features are combined together for further processing in order to extract the semantic information encoded in the point cloud. Previous networks adopt all the same local neighborhoods at different layers, as they utilize the same metric on fixed input point coordinates to define local neighborhoods. It is easy to implement but not necessarily optimal. Ideally local neighborhoods should be different at different layers so as to adapt to layer dynamics for efficient feature learning. One way to achieve this is to learn different transformations of the input point cloud at each layer, and then extract features from local neighborhoods defined on transformed coordinates.
In this work, we propose a novel end-to-end approach to learn different non-rigid transformations of the input point cloud for different local neighborhoods at each layer. We propose both linear (affine) and non-linear (projective and deformable) spatial transformers for 3D point clouds. With spatial transformers on the ShapeNet part segmentation dataset, the network achieves higher accuracy for all categories, specifically with 8% gain on earphones and rockets. The proposed methods also outperform the state-of-the-art methods in several other point cloud processing tasks (classification, semantic segmentation and detection). Visualizations show that spatial transformers can learn features more efficiently by dynamically altering local neighborhoods according to the geometric and semantic information of 3D shapes regardless of variations in a category.
Public Video

Code

Citation
@article{spn3dpointclouds,
author = {Jiayun Wang and
Rudrasis Chakraborty and
Stella X. Yu},
title = {Spatial Transformer for 3D Points},
journal = {CoRR},
volume = {abs/1906.10887},
year = {2019},
url = {http://arxiv.org/abs/1906.10887},
}