Publications
Asterisk indicates equal contribution.
An up-to-date list is available on Google Scholar.
Preprints
2026
- arXiv
 Inference Time Optimization with Confidence DynamicsYu Wang , Minghao Liu , Jiayun Wang , Jinrui Huang, Ankit Shah, and Wei WeiarXiv preprint, 2026
Inference Time Optimization with Confidence DynamicsYu Wang , Minghao Liu , Jiayun Wang , Jinrui Huang, Ankit Shah, and Wei WeiarXiv preprint, 2026

2025
- arXiv
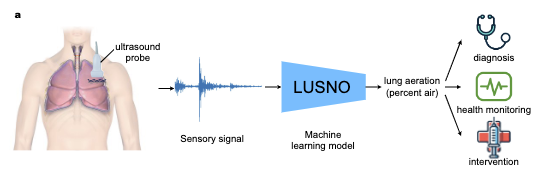 Ultrasound Lung Aeration Map via Physics-Aware Neural OperatorsJiayun Wang, Oleksii Ostras, Masashi Sode, Bahareh Tolooshams, Zongyi Li, Kamyar Azizzadenesheli, and 2 more authorsarXiv 2501.01157, 2025
Ultrasound Lung Aeration Map via Physics-Aware Neural OperatorsJiayun Wang, Oleksii Ostras, Masashi Sode, Bahareh Tolooshams, Zongyi Li, Kamyar Azizzadenesheli, and 2 more authorsarXiv 2501.01157, 2025Lung ultrasound is a growing modality in clinics for diagnosing and monitoring acute and chronic lung diseases due to its low cost and accessibility. Lung ultrasound works by emitting diagnostic pulses, receiving pressure waves and converting them into radio frequency (RF) data, which are then processed into B-mode images with beamformers for radiologists to interpret. However, unlike conventional ultrasound for soft tissue anatomical imaging, lung ultrasound interpretation is complicated by complex reverberations from the pleural interface caused by the inability of ultrasound to penetrate air. The indirect B-mode images make interpretation highly dependent on reader expertise, requiring years of training, which limits its widespread use despite its potential for high accuracy in skilled hands. To address these challenges and democratize ultrasound lung imaging as a reliable diagnostic tool, we propose LUNA, an AI model that directly reconstructs lung aeration maps from RF data, bypassing the need for traditional beamformers and indirect interpretation of B-mode images.
- arXiv
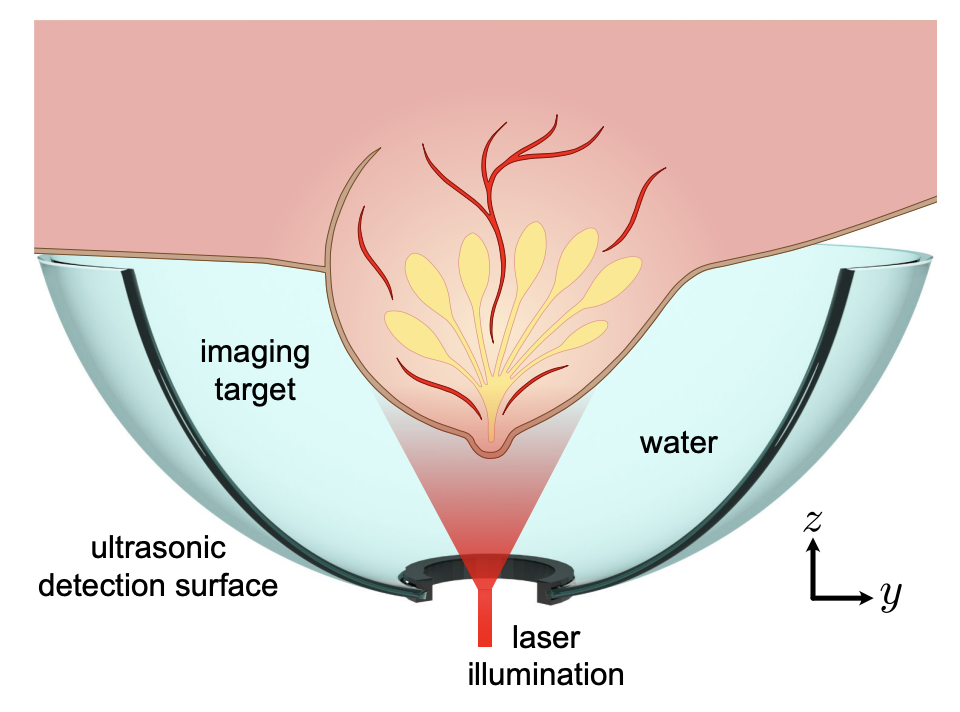 Accelerating 3D Photoacoustic Computed Tomography with End-to-End Physics-Aware Neural OperatorsJiayun Wang, Yousuf Aborahama, Arya Khokhar, Yang Zhang , Chuwei Wang, Karteekeya Sastry, and 7 more authorsarXiv 2509.09894, 2025
Accelerating 3D Photoacoustic Computed Tomography with End-to-End Physics-Aware Neural OperatorsJiayun Wang, Yousuf Aborahama, Arya Khokhar, Yang Zhang , Chuwei Wang, Karteekeya Sastry, and 7 more authorsarXiv 2509.09894, 2025Photoacoustic computed tomography (PACT) combines optical contrast with ultrasonic resolution, achieving deep-tissue imaging beyond the optical diffusion limit. While three-dimensional PACT systems enable high-resolution volumetric imaging for applications spanning transcranial to breast imaging, current implementations require dense transducer arrays and prolonged acquisition times, limiting clinical translation. We introduce Pano (PACT imaging neural operator), an end-to-end physics-aware model that directly learns the inverse acoustic mapping from sensor measurements to volumetric reconstructions. Unlike existing approaches (e.g. universal back-projection algorithm), Pano learns both physics and data priors while also being agnostic to the input data resolution. Pano employs spherical discrete-continuous convolutions to preserve hemispherical sensor geometry, incorporates Helmholtz equation constraints to ensure physical consistency and operates resolutionindependently across varying sensor configurations. We demonstrate the robustness and efficiency of Pano in reconstructing high-quality images from both simulated and real experimental data, achieving consistent performance even with significantly reduced transducer counts and limited-angle acquisition configurations. The framework maintains reconstruction fidelity across diverse sparse sampling patterns while enabling real-time volumetric imaging capabilities. This advancement establishes a practical pathway for making 3D PACT more accessible and feasible for both preclinical research and clinical applications, substantially reducing hardware requirements without compromising image reconstruction quality.
- arXiv
 Variable Sampling for Fast and Efficient Functional Ultrasound Imaging using Neural OperatorsBahareh Tolooshams , Lydia Lin, Thierri Callier , Jiayun Wang, Sanvi Pal, Aditi Chandrashekar, and 7 more authorsbiorxiv 2025.04.16.649237, 2025
Variable Sampling for Fast and Efficient Functional Ultrasound Imaging using Neural OperatorsBahareh Tolooshams , Lydia Lin, Thierri Callier , Jiayun Wang, Sanvi Pal, Aditi Chandrashekar, and 7 more authorsbiorxiv 2025.04.16.649237, 2025Functional ultrasound (fUS) is an emerging technique for non-invasive neuroimaging that infers neural activity by detecting changes in blood volume. fUS has found its applications in neuroscience studies with freely moving animals and brain-computer interfaces (BCIs) as it offers minimally invasive high spatiotemporal resolution and is a low-cost and portable technology compared to prior neurorecording techniques such as electrophysiology and functional magnetic resonance imaging (fMRI). However, the current classical fUS methods require a relatively large number of compounded images to successfully remove tissue clutter. This property has not only caused computational, memory, and communication complexity for fUS hardware technologies but also has resulted in an undesirable wait period to construct one brain image. The latter, particularly, has negatively impacted the use of fUS for real-time BCIs. Therefore we propose accelerated fUS through a deep learning technique called the neural operator for functional ultrasound (NO-fUS). NO-fUS tackles the technical challenges: it reduces the wait period of frame collections by 90% and the sampling rate at inference time by 50%. This extensive reduction on the number of input frames is a step toward more efficient fUS technology such as for 3D volumetric imaging fUS technology, reducing number of ultrasound pulses needed to image and, in turn, reduce potential probe heating and computational cost. Unlike conventional, data-driven deep neural architecture, NO-fUS is generalizable across experiment sessions and animals; we highlight this generalization in mouse, monkey, and human data. Finally, we demonstrate the BCI applications of NO-fUS in behavioral decoding. Specifically, our results suggest that NO-fUS not only offers high-quality images, but also preserves behavior-related information required to decode the subject’s thoughts and planning.
- arXiv
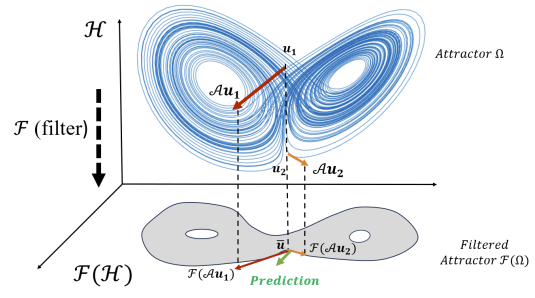 Beyond Closure Models: Learning Chaotic-Systems via Physics-Informed Neural OperatorsIn arXiv 2408.05177, 2025
Beyond Closure Models: Learning Chaotic-Systems via Physics-Informed Neural OperatorsIn arXiv 2408.05177, 2025Accurately predicting the long-term behavior of chaotic systems is crucial for various applications such as climate modeling. However, achieving such predictions typically requires iterative computations over a dense spatiotemporal grid to account for the unstable nature of chaotic systems, which is expensive and impractical in many real-world situations. An alternative approach to such a full-resolved simulation is using a coarse grid and then correcting its errors through a \textitclosure model, which approximates the overall information from fine scales not captured in the coarse-grid simulation. Recently, ML approaches have been used for closure modeling, but they typically require a large number of training samples from expensive fully-resolved simulations (FRS). In this work, we prove an even more fundamental limitation, i.e., the standard approach to learning closure models suffers from a large approximation error for generic problems, no matter how large the model is, and it stems from the non-uniqueness of the mapping. We propose an alternative end-to-end learning approach using a physics-informed neural operator (PINO) that overcomes this limitation by not using a closure model or a coarse-grid solver.




Conference & Journal Articles
2025
- CVPR
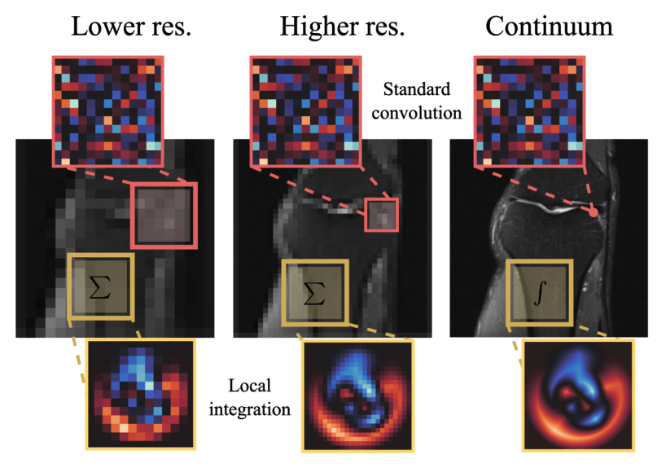 A Unified Model for Compressed Sensing MRI Across Undersampling PatternsArmeet Jatyani* , Jiayun Wang*, Aditi Chandrashekar, Zihui Wu, Miguel Liu-Schiaffini, Bahareh Tolooshams, and 1 more authorIn Conference on Computer Vision and Pattern Recognition (CVPR) Proceedings, 2025
A Unified Model for Compressed Sensing MRI Across Undersampling PatternsArmeet Jatyani* , Jiayun Wang*, Aditi Chandrashekar, Zihui Wu, Miguel Liu-Schiaffini, Bahareh Tolooshams, and 1 more authorIn Conference on Computer Vision and Pattern Recognition (CVPR) Proceedings, 2025CCompressed Sensing MRI reconstructs images of the body’s internal anatomy from undersampled measurements, thereby reducing the scan time - the time subjects need to remain still. Recently, deep neural networks have shown great potential for reconstructing high-fidelity images from highly undersampled measurements in the frequency space. However, one needs to train multiple models for different undersampling patterns and desired output image resolutions, since most networks operate on a fixed discretization. Such approaches are highly impractical in clinical settings, where undersampling patterns and image resolutions are frequently changed to accommodate different real-time imaging and diagnostic requirements. We propose a unified model robust to different measurement undersampling patterns and image resolutions in compressed sensing MRI. Our model is based on neural operators, a discretization-agnostic architecture. Neural operators are employed in both image and measurement space, which capture local and global image features for MRI reconstruction. Empirically, we achieve consistent performance across different undersampling rates and patterns, with an average 11 percent SSIM and 4dB PSNR improvement over a state-of-the-art CNN, End-to-End VarNet. For efficiency, our inference speed is also 1,400x faster than diffusion methods. The resolution-agnostic design also enhances zero-shot super-resolution and extended field of view in reconstructed images. Our unified model offers a versatile solution for MRI, adapting seamlessly to various measurement undersampling and imaging resolutions, making it highly effective for flexible and reliable clinical imaging.
- TS4H @ NeurIPS
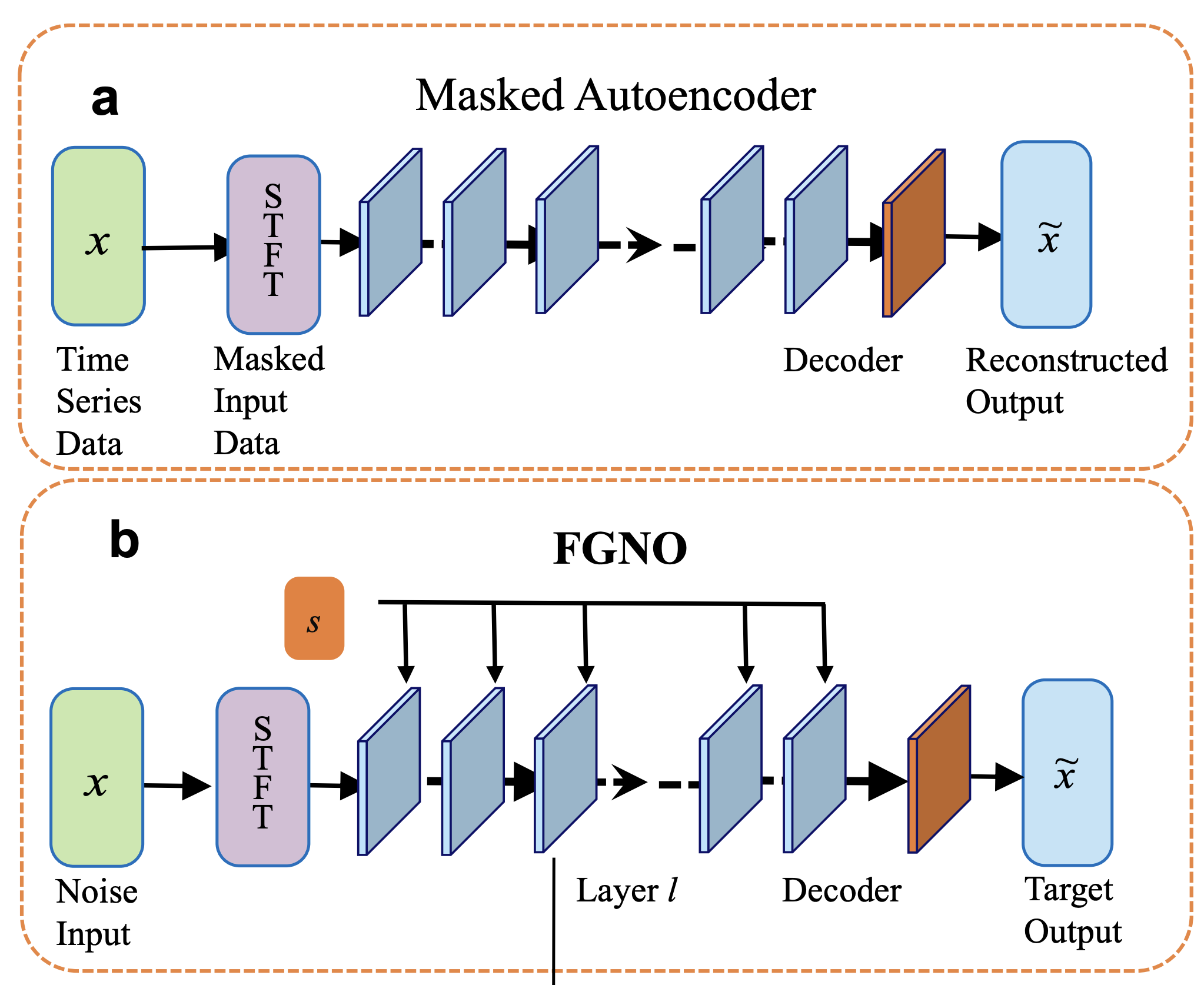 Flow-Guided Neural Operator for Self-Supervised Learning on Time Series DataDuy Nguyen* , Jiayun Wang* , Jiachen Yao*, Julius Berner, and Anima AnandkumarIn NeurIPS Workshop, 2025
Flow-Guided Neural Operator for Self-Supervised Learning on Time Series DataDuy Nguyen* , Jiayun Wang* , Jiachen Yao*, Julius Berner, and Anima AnandkumarIn NeurIPS Workshop, 2025Self-supervised learning (SSL) is a powerful paradigm for learning from unlabeled time-series data. However, traditional methods such as masked autoencoders (MAEs) rely on reconstructing inputs from a fixed, predetermined masking ratio. Instead of this static design, we propose treating the corruption level as a new degree of freedom for representation learning. To achieve this, we introduce the FlowGuided Neural Operator (FGNO), the first framework to combine operator learning with flow matching for SSL training. By leveraging Short-Time Fourier Transform (STFT) to enable computation under different time resolutions, our approach effectively learns mappings in functional spaces. We extract a rich hierarchy of features by tapping into different network layers (l) and generative time steps (s) that apply varying strengths of noise to the input data. This enables the extraction of versatile, task-specific representations—from low-level patterns to high-level semantics—all from a single model. We evaluated our model performance on two different biomedical domains, where our flow-based operator significantly outperforms established baselines. When applied to a sleep health dataset, it achieved 16% RMSE improvement over MAE in skin temperature regression, while showing 1% AUROC gain in classification tasks. On a neural decoding task for binary speech classification, our approach achieves a significant 20% AUROC improvement compared to MAE, highlighting its ability to learn powerful, task-adaptable representations.
- 3DV
 Open Vocabulary Monocular 3D Object DetectionJin Yao, Hao Gu , Xuweiyi Chen , Jiayun Wang, and Zezhou ChengIn 2025 International Conference on 3D Vision (3DV), 2025
Open Vocabulary Monocular 3D Object DetectionJin Yao, Hao Gu , Xuweiyi Chen , Jiayun Wang, and Zezhou ChengIn 2025 International Conference on 3D Vision (3DV), 2025In this work, we pioneer the study of open-vocabulary monocular 3D object detection, a novel task that aims to detect and localize objects in 3D space from a single RGB image without limiting detection to a predefined set of categories. We formalize this problem, establish baseline methods, and introduce a class-agnostic approach that leverages open-vocabulary 2D detectors and lifts 2D bounding boxes into 3D space. Our approach decouples the recognition and localization of objects in 2D from the task of estimating 3D bounding boxes, enabling generalization across unseen categories. Additionally, we propose a target-aware evaluation protocol to address inconsistencies in existing datasets, improving the reliability of model performance assessment. Extensive experiments on the Omni3D dataset demonstrate the effectiveness of the proposed method in zero-shot 3D detection for novel object categories, validating its robust generalization capabilities. Our method and evaluation protocols contribute towards the development of open-vocabulary object detection models that can effectively operate in real-world, category-diverse environments.



2024
- ECCV
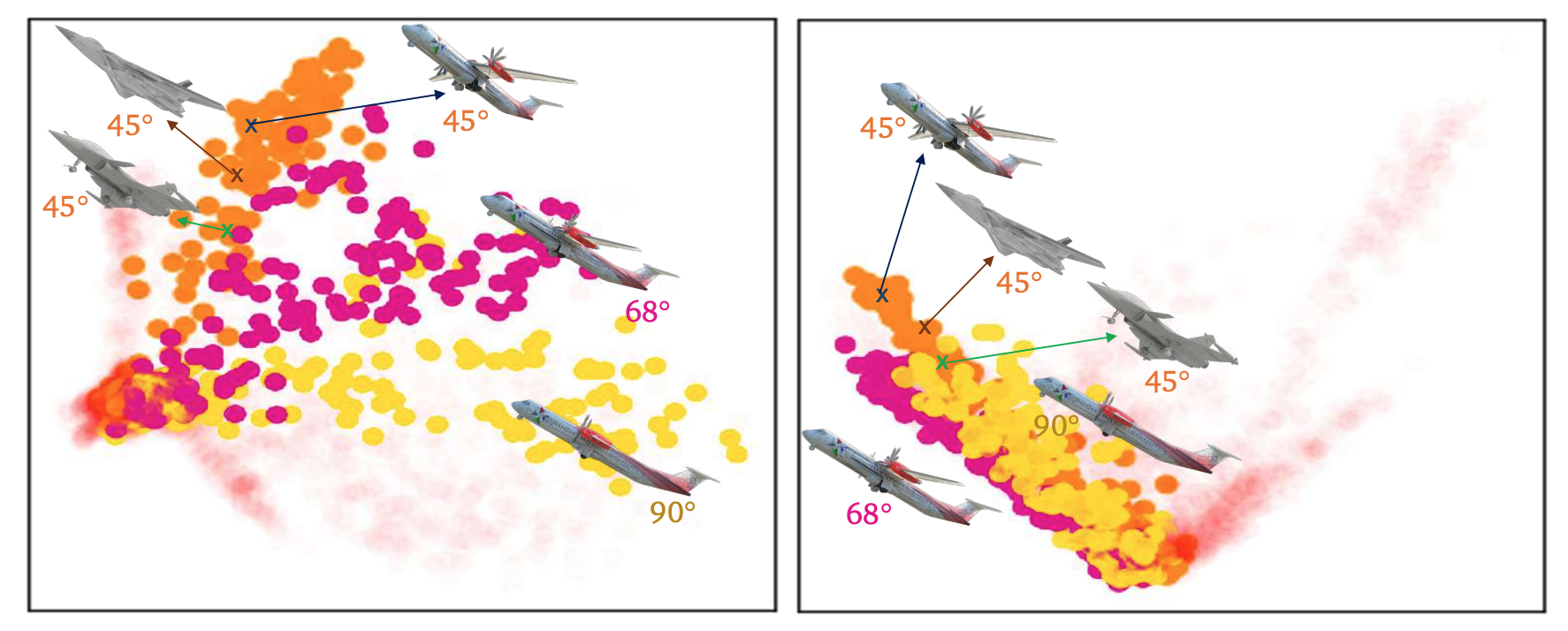 Pose-Aware Self-Supervised Learning with Viewpoint Trajectory RegularizationJiayun Wang, Yubei Chen, and Stella YuIn European Conference on Computer Vision (ECCV), 2024
Pose-Aware Self-Supervised Learning with Viewpoint Trajectory RegularizationJiayun Wang, Yubei Chen, and Stella YuIn European Conference on Computer Vision (ECCV), 2024The paper was selected as an oral presentation (2.3%).
Learning visual features from unlabeled images has proven successful for semantic categorization, often by mapping different views of the same object to the same feature to achieve recognition invariance. However, visual recognition involves not only identifying what an object is but also understanding how it is presented. For example, seeing a car from the side versus head-on is crucial for deciding whether to stay put or jump out of the way. While unsupervised feature learning for downstream viewpoint reasoning is important, it remains under-explored, partly due to the lack of a standardized evaluation method and benchmarks. We introduce a new dataset of adjacent image triplets obtained from a viewpoint trajectory, without any semantic or pose labels. We benchmark both semantic classification and pose estimation accuracies on the same visual feature. Additionally, we propose a viewpoint trajectory regularization loss for learning features from unlabeled image triplets. Our experiments demonstrate that this approach helps develop a visual representation that encodes object identity and organizes objects by their poses, retaining semantic classification accuracy while achieving emergent global pose awareness and better generalization to novel objects.
- MICCAI
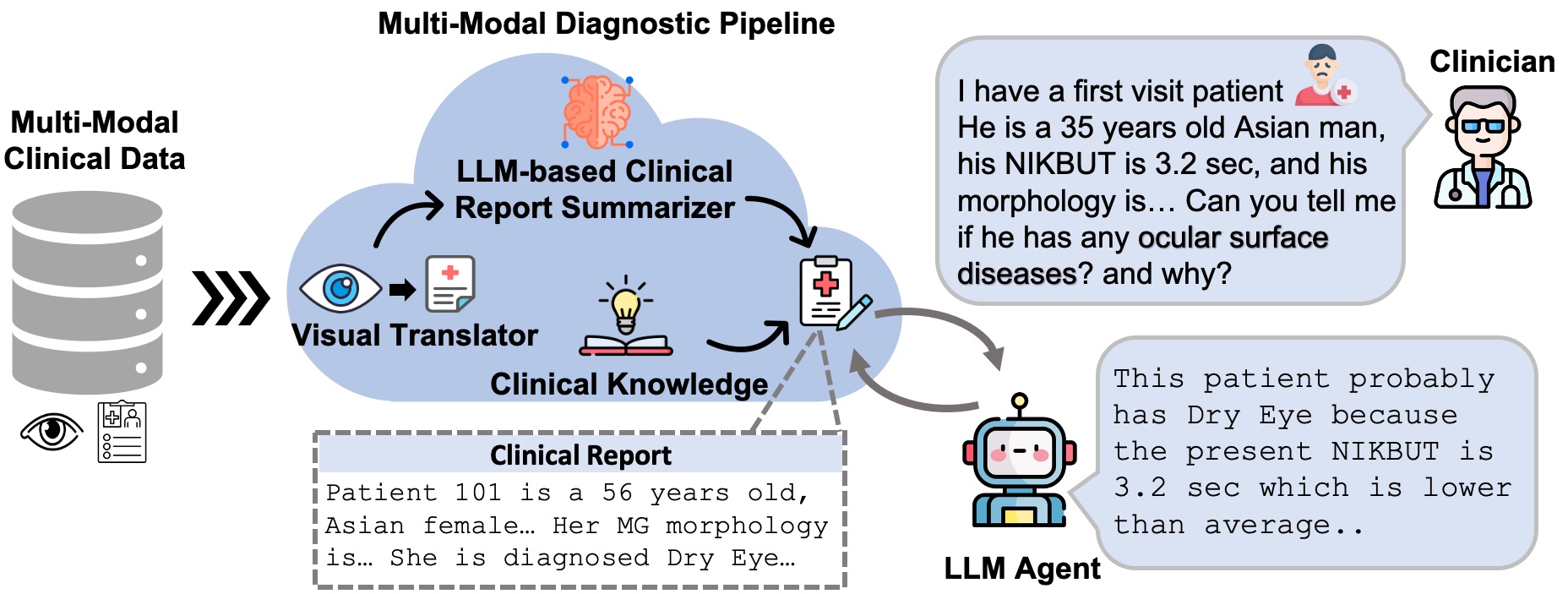 Insight: A Multi-Modal Diagnostic Pipeline using LLMs for Ocular Surface Disease DiagnosisChun-Hsiao Yeh , Jiayun Wang, Andrew D. Graham , Andrea J. Liu, Bo Tan, Yubei Chen, and 2 more authorsIn Medical Image Computing and Computer-Assisted Intervention (MICCAI) Proceedings, 2024
Insight: A Multi-Modal Diagnostic Pipeline using LLMs for Ocular Surface Disease DiagnosisChun-Hsiao Yeh , Jiayun Wang, Andrew D. Graham , Andrea J. Liu, Bo Tan, Yubei Chen, and 2 more authorsIn Medical Image Computing and Computer-Assisted Intervention (MICCAI) Proceedings, 2024Accurate diagnosis of ocular surface diseases is critical in optometry and ophthalmology, which hinge on integrating clinical data sources (e.g., meibography imaging and clinical metadata). Traditional human assessments lack precision in quantifying clinical observations, while current machine-based methods often treat diagnoses as multi-class classification problems, limiting the diagnoses to a predefined closed-set of curated answers without reasoning the clinical relevance of each variable to the diagnosis. To tackle these challenges, we introduce an innovative multi-modal diagnostic pipeline (MDPipe) by employing large language models (LLMs) for ocular surface disease diagnosis. We first employ a visual translator to interpret meibography images by converting them into quantifiable morphology data, facilitating their integration with clinical metadata and enabling the communication of nuanced medical insight to LLMs. To further advance this communication, we introduce a LLM-based summarizer to contextualize the insight from the combined morphology and clinical metadata, and generate clinical report summaries. Finally, we refine the LLMs’ reasoning ability with domain-specific insight from real-life clinician diagnoses. Our evaluation across diverse ocular surface disease diagnosis benchmarks demonstrates that MDPipe outperforms existing standards, including GPT-4, and provides clinically sound rationales for diagnoses.
- ML4H
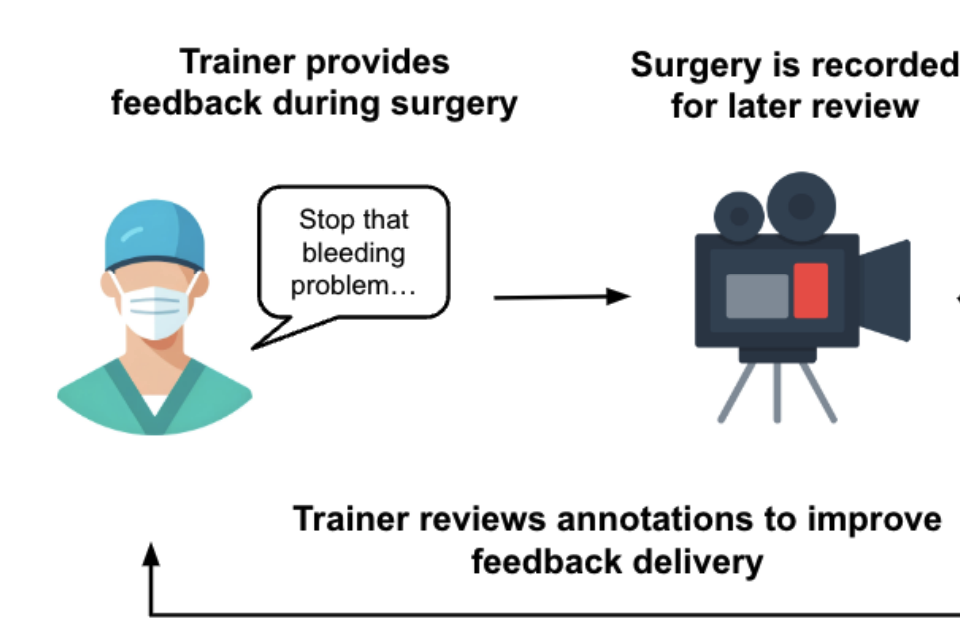 Multi-Modal Self-Supervised Learning for Surgical Feedback Effectiveness AssessmentArushi Gupta, Rafal Kocielnik , Jiayun Wang, Firdavs Nasriddinov, Cherine Yang, Elyssa Wong, and 2 more authorsIn Machine Learning for Health, PMLR, 2024
Multi-Modal Self-Supervised Learning for Surgical Feedback Effectiveness AssessmentArushi Gupta, Rafal Kocielnik , Jiayun Wang, Firdavs Nasriddinov, Cherine Yang, Elyssa Wong, and 2 more authorsIn Machine Learning for Health, PMLR, 2024The paper won the best paper award at 2024 Machine Learning for Health Conference.
During surgical training, real-time feedback from trainers to trainees is important for preventing errors and enhancing long-term skill acquisition. Accurately predicting the effectiveness of this feedback—specifically whether it leads to a change in trainee behavior, which is crucial for developing methods to improve surgical training and education. However, relying on human annotations to assess feedback effectiveness is labor-intensive and prone to biases, highlighting the need for an automated, scalable, and objective approach. Developing such a system is challenging, as it requires understanding both the verbal feedback delivered by the trainer and the visual context of the real-time surgical scene. To address this, we propose a method that integrates information from transcribed verbal feedback and corresponding surgical video to predict feedback effectiveness.
- Heliyon
 A Machine Learning Approach to Predicting Dry Eye-Related Signs, Symptoms and DiagnosesAndrew D Graham, Tejasvi Kothapalli , Jiayun Wang, Jennifer Ding, Vivien Tse, Penny Asbell, and 2 more authorsHeliyon, 2024
A Machine Learning Approach to Predicting Dry Eye-Related Signs, Symptoms and DiagnosesAndrew D Graham, Tejasvi Kothapalli , Jiayun Wang, Jennifer Ding, Vivien Tse, Penny Asbell, and 2 more authorsHeliyon, 2024To use artificial intelligence to identify relationships between morphological characteristics of the Meibomian glands (MGs), subject factors, clinical outcomes, and subjective symptoms of dry eye. A deep learning model was trained to take meibography as input, segment the individual MG in the images, and learn their detailed morphological features. Morphological characteristics were then combined with clinical and symptom data in prediction models of MG function, tear film stability, ocular surface health, and subjective discomfort and dryness. The models were analyzed to identify the most heavily weighted features used by the algorithm for predictions. Machine learning-derived MG morphological characteristics were found to be important in predicting multiple signs, symptoms, and diagnoses related to MG dysfunction and dry eye. This deep learning method illustrates the rich clinical information that detailed morphological analysis of the MGs can provide, and shows promise in advancing our understanding of the role of MG morphology in ocular surface health.
- Nature Portfolio
 Artificial Intelligence Models Utilize Lifestyle Factors to Predict Dry Eye Related OutcomesAndrew D. Graham , Jiayun Wang, Tejasvi Kothapalli, Jennifer Ding, Helen Tasho, Alisa Molina, and 4 more authorsNature Scientific Reports, 2024
Artificial Intelligence Models Utilize Lifestyle Factors to Predict Dry Eye Related OutcomesAndrew D. Graham , Jiayun Wang, Tejasvi Kothapalli, Jennifer Ding, Helen Tasho, Alisa Molina, and 4 more authorsNature Scientific Reports, 2024Purpose: To examine and interpret machine learning models that predict dry eye (DE)-related clinical signs, subjective symptoms, and clinician diagnoses by heavily weighting lifestyle factors in the predictions. Methods: Machine learning models were trained to take clinical assessments of the ocular surface, eyelids, and tear film, combined with symptom scores from validated questionnaire instruments for DE and clinician diagnoses of ocular surface diseases, and perform a classification into DE-related outcome categories. Outcomes are presented for which the data-driven algorithm identified subject characteristics, lifestyle, behaviors, or environmental exposures as heavily weighted predictors. Models were assessed by 5-fold cross-validation accuracy and class-wise statistics of the predictors. Conclusions: The results emphasize the importance of lifestyle, subject, and environmental characteristics in the etiology of ocular surface disease. Lifestyle factors should be taken into account in clinical research and care to a far greater extent than has been the case to date.





2023
- Patent
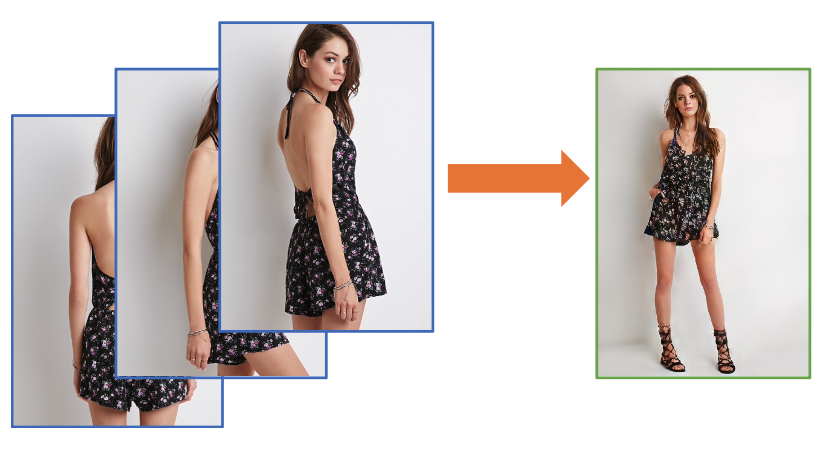 Human Reposing and Virtual Try-On from Multi-View ImagesJiayun Wang, Amin Kheradmand, and Himanshu Arora2023
Human Reposing and Virtual Try-On from Multi-View ImagesJiayun Wang, Amin Kheradmand, and Himanshu Arora2023We study human reposing and virtual try-on from multi- view images. Unlike existing works which take a single im- age as an input, we learn from multi-view images which are readily available in most fashion datasets and provide rich information on the geometric structures and textures of the human and garments. To this end, since each input view provides partial observation of the person and under- lying garments, an appropriate design of parsing and fusing multi-view information for the target image proves essen- tial. We propose a novel framework for warping and fus- ing reference human images from multiple and varied view- points and poses to a target viewpoint and pose. The frame- work is effective as it considers both 3D human body geom- etry and 2D photorealism. We also introduce a conditional patch discriminator to further improve image quality. The proposed method outperforms state-of-the-art single-view methods. Specifically, in our experiments with the Deep- Fashion dataset, we show significant improvements in terms of visual quality, PSNR, SSIM, FID and LPIPS metrics over the existing state-of-the-art approaches.
- WACV
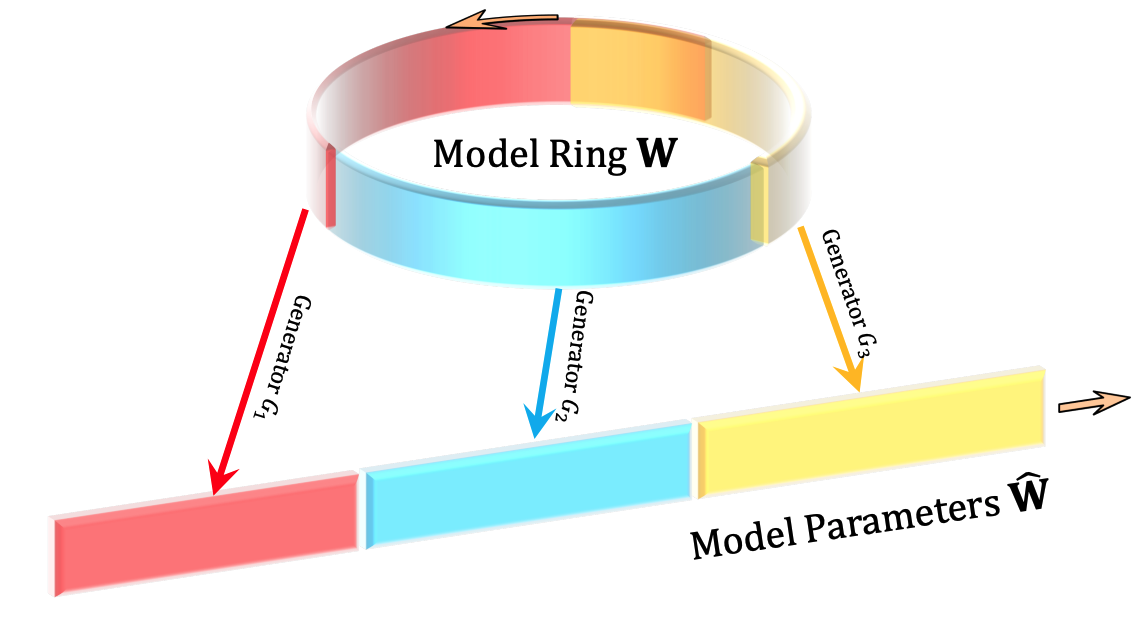 Compact and Optimal Deep Learning with Recurrent Parameter GeneratorsIn Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2023
Compact and Optimal Deep Learning with Recurrent Parameter GeneratorsIn Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2023Deep learning has achieved tremendous success by training increasingly large models, which are then compressed for practical deployment. We propose a drastically different approach to compact and optimal deep learning: We decouple the Degrees of freedom (DoF) and the actual number of parameters of a model, optimize a small DoF with predefined random linear constraints for a large model of arbitrary architecture, in one-stage end-to-end learning. Specifically, we create a recurrent parameter generator (RPG), which repeatedly fetches parameters from a ring and unpacks them onto a large model with random permutation and sign flipping to promote parameter decorrelation. We show that gradient descent can automatically find the best model under constraints with faster convergence. Our extensive experimentation reveals a log-linear relationship between model DoF and accuracy. Our RPG demonstrates remarkable DoF reduction and can be further pruned and quantized for additional run-time performance gain. For example, in terms of top-1 accuracy on ImageNet, RPG achieves 96% of ResNet18’s performance with only 18% DoF (the equivalent of one convolutional layer) and 52% of ResNet34’s performance with only 0.25% DoF! Our work shows a significant potential of constrained neural optimization in compact and optimal deep learning.
- ML4H
 Deep Multimodal Fusion for Surgical Feedback ClassificationRafal Kocielnik, Elyssa Y Wong, Timothy N Chu , Lydia Lin, De-An Huang , Jiayun Wang, and 2 more authorsIn Machine Learning for Health, PMLR, 2023
Deep Multimodal Fusion for Surgical Feedback ClassificationRafal Kocielnik, Elyssa Y Wong, Timothy N Chu , Lydia Lin, De-An Huang , Jiayun Wang, and 2 more authorsIn Machine Learning for Health, PMLR, 2023The paper won the best paper award at 2023 Machine Learning for Health Conference.
Quantification of real-time informal feedback delivered by an experienced surgeon to a trainee during surgery is important for skill improvements in surgical training. Such feedback in the live operating room is inherently multimodal, consisting of verbal conversations (e.g., questions and answers) as well as non-verbal elements (e.g., through visual cues like pointing to anatomic elements). In this work, we leverage a clinically-validated five-category classification of surgical feedback: “Anatomic” , “Technical” , “Procedural” , “Praise” and “Visual Aid” . We then develop a multi-label machine learning model to classify these five categories of surgical feedback from inputs of text, audio, and video modalities. The ultimate goal of our work is to help automate the annotation of real-time contextual surgical feedback at scale. This work offers an important first look at the feasibility of automated classification of real-world live surgical feedback based on text, audio, and video modalities.



2022
- TPAMI
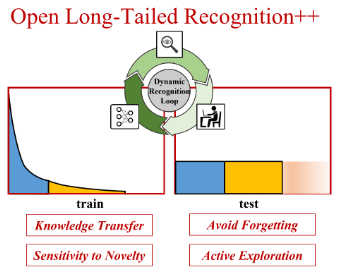 Open Long-Tailed Recognition in a Dynamic WorldIEEE Transactions on Pattern Analysis and Machine Intelligence, 2022
Open Long-Tailed Recognition in a Dynamic WorldIEEE Transactions on Pattern Analysis and Machine Intelligence, 2022Real world data often exhibits a long-tailed and open-ended (i.e., with unseen classes) distribution. A practical recognition system must balance between majority (head) and minority (tail) classes, generalize across the distribution, and acknowledge novelty upon the instances of unseen classes (open classes). We define Open Long-Tailed Recognition++ (OLTR++) as learning from such naturally distributed data and optimizing for the classification accuracy over a balanced test set which includes both known and open classes. OLTR++ handles imbalanced classification, few-shot learning, open-set recognition, and active learning in one integrated algorithm, whereas existing classification approaches often focus only on one or two aspects and deliver poorly over the entire spectrum. The key challenges are: 1) how to share visual knowledge between head and tail classes, 2) how to reduce confusion between tail and open classes, and 3) how to actively explore open classes with learned knowledge. Our algorithm, OLTR++, maps images to a feature space such that visual concepts can relate to each other through a memory association mechanism and a learned metric (dynamic meta-embedding) that both respects the closed world classification of seen classes and acknowledges the novelty of open classes. Additionally, we propose an active learning scheme based on visual memory, which learns to recognize open classes in a data-efficient manner for future expansions. On three large-scale open long-tailed datasets we curated from ImageNet (object-centric), Places (scene-centric), and MS1M (face-centric) data, as well as three standard benchmarks (CIFAR-10-LT, CIFAR-100-LT, and iNaturalist-18), our approach, as a unified framework, consistently demonstrates competitive performance. Notably, our approach also shows strong potential for the active exploration of open classes and the fairness analysis of minority groups.
- ECCV
 Unsupervised Scene Sketch to Photo SynthesisJiayun Wang, Sangryul Jeon, Stella Yu, Xi Zhang, Himanshu Arora, and Yu LouIn European Conference on Computer Vision (ECCV), 2022
Unsupervised Scene Sketch to Photo SynthesisJiayun Wang, Sangryul Jeon, Stella Yu, Xi Zhang, Himanshu Arora, and Yu LouIn European Conference on Computer Vision (ECCV), 2022Sketches make an intuitive and powerful visual expression as they are fast executed freehand drawings. We present a method for synthesizing realistic photos from scene sketches. Without the need for sketch and photo pairs, our framework directly learns from readily available large-scale photo datasets in an unsupervised manner. To this end, we introduce a standardization module that provides pseudo sketch-photo pairs during training by converting photos and sketches to a standardized domain, i.e. the edge map. The reduced domain gap between sketch and photo also allows us to disentangle them into two components: holistic scene structures and low-level visual styles such as color and texture. Taking this advantage, we synthesize a photo-realistic image by combining the structure of a sketch and the visual style of a reference photo. Extensive experimental results on perceptual similarity metrics and human perceptual studies show the proposed method could generate realistic photos with high fidelity from scene sketches and outperform state-of-the-art photo synthesis baselines. We also demonstrate that our framework facilitates a controllable manipulation of photo synthesis by editing strokes of corresponding sketches, delivering more fine-grained details than previous approaches that rely on region-level editing.
- Nature Portfolio
 Predicting Demographics from Meibography Using Deep LearningNature Scientific reports, 2022
Predicting Demographics from Meibography Using Deep LearningNature Scientific reports, 2022This study introduces a deep learning approach to predicting demographic features from meibography images. A total of 689 meibography images with corresponding subject demographic data were used to develop a deep learning model for predicting gland morphology and demographics from images. The model achieved on average 77%, 76%, and 86% accuracies for predicting Meibomian gland morphological features, subject age, and ethnicity, respectively. The model was further analyzed to identify the most highly weighted gland morphological features used by the algorithm to predict demographic characteristics. The two most important gland morphological features for predicting age were the percent area of gland atrophy and the percentage of ghost glands. The two most important morphological features for predicting ethnicity were gland density and the percentage of ghost glands. The approach offers an alternative to traditional associative modeling to identify relationships between Meibomian gland morphological features and subject demographic characteristics. This deep learning methodology can currently predict demographic features from de-identified meibography images with better than 75% accuracy, a number which is highly likely to improve in future models using larger training datasets, which has significant implications for patient privacy in biomedical imaging.
- DIRA @ ECCV
 3D Shape Reconstruction from Free-Hand SketchesIn European Conference on Computer Vision (ECCV), 2022
3D Shape Reconstruction from Free-Hand SketchesIn European Conference on Computer Vision (ECCV), 2022The paper was selected as an spotlight presentation.
- MI @ NeurIPS
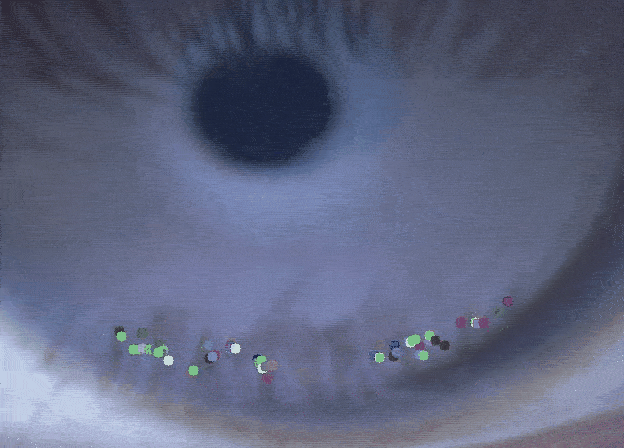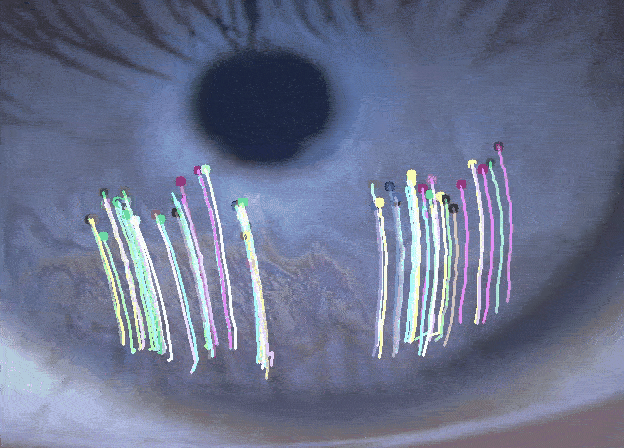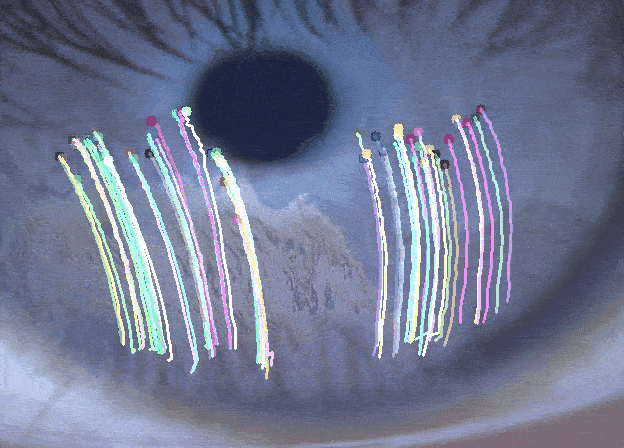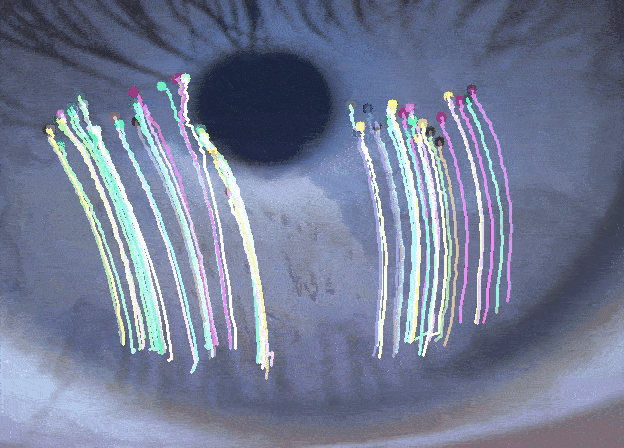 Tracking the Dynamics of the Tear Film Lipid LayerTejasvi Kothapalli, Charlie Shou, Jennifer Ding , Jiayun Wang, Andrew D Graham, Tatyana Svitova, and 2 more authorsIn NeurIPS Workshop, 2022
Tracking the Dynamics of the Tear Film Lipid LayerTejasvi Kothapalli, Charlie Shou, Jennifer Ding , Jiayun Wang, Andrew D Graham, Tatyana Svitova, and 2 more authorsIn NeurIPS Workshop, 2022Dry Eye Disease (DED) is one of the most common ocular diseases: over five percent of US adults suffer from DED [4]. Tear film instability is a known factor for DED, and is thought to be regulated in large part by the thin lipid layer that covers and stabilizes the tear film. In order to aid eye related disease diagnosis, this work proposes a novel paradigm in using computer vision techniques to numerically analyze the tear film lipid layer (TFLL) spread. Eleven videos of the tear film lipid layer spread are collected with a micro-interferometer and a subset are annotated. A tracking algorithm relying on various pillar computer vision techniques is developed.



2021
- TPAMI
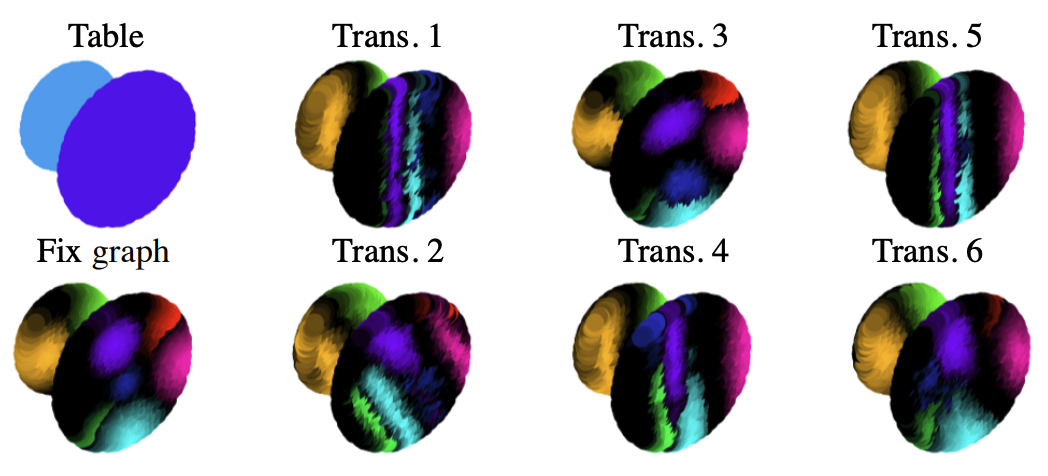 Spatial Transformer for 3D Point CloudsJiayun Wang, Rudrasis Chakraborty, and Stella YuIEEE Transactions on Pattern Analysis and Machine Intelligence, 2021
Spatial Transformer for 3D Point CloudsJiayun Wang, Rudrasis Chakraborty, and Stella YuIEEE Transactions on Pattern Analysis and Machine Intelligence, 2021Deep neural networks can efficiently process 3D point clouds. At each point convolution layer, local features can be learned from local neighborhoods of the point cloud. These features are combined together for further processing in order to extract the semantic information encoded in the point cloud. Previous networks adopt all the same local neighborhoods at different layers, as they utilize the same metric on fixed input point coordinates to define local neighborhoods. It is easy to implement but not necessarily optimal. Ideally local neighborhoods should be different at different layers so as to adapt to layer dynamics for efficient feature learning. One way to achieve this is to learn different transformations of the input point cloud at each layer, and then extract features from local neighborhoods defined on transformed coordinates. In this work, we propose a novel end-to-end approach to learn different non-rigid transformations of the input point cloud for different local neighborhoods at each layer. We propose both linear (affine) and non-linear (projective and deformable) spatial transformers for 3D point clouds.
- OVS
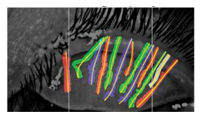 Quantifying meibomian gland morphology using artificial intelligenceJiayun Wang , Shixuan Li , Thao N Yeh, Rudrasis Chakraborty, Andrew D Graham, Stella Yu, and 1 more authorOptometry and Vision Science, 2021
Quantifying meibomian gland morphology using artificial intelligenceJiayun Wang , Shixuan Li , Thao N Yeh, Rudrasis Chakraborty, Andrew D Graham, Stella Yu, and 1 more authorOptometry and Vision Science, 2021Quantifying meibomian gland morphology from meibography images is used for the diagnosis, treatment, and management of meibomian gland dysfunction in clinics. A novel and automated method is described for quantifying meibomian gland morphology from meibography images. Meibomian gland morphological abnormality is a common clinical sign of meibomian gland dysfunction, yet there exist no automated methods that provide standard quantifications of morphological features for individual glands. This study introduces an automated artificial intelligence approach to segmenting individual meibomian gland regions in infrared meibography images and analyzing their morphological features.


2020
- CVPR
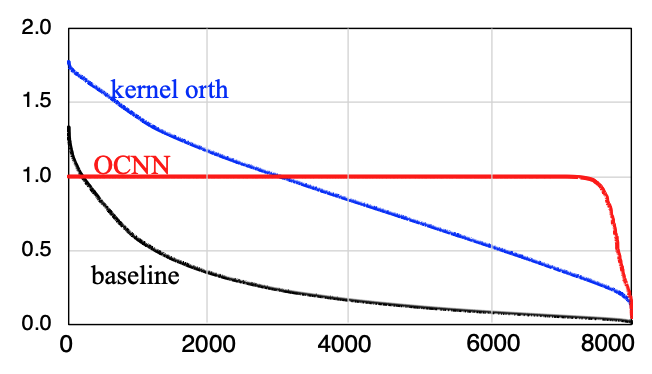 Orthogonal Convolutional Neural NetworksIn Conference on Computer Vision and Pattern Recognition (CVPR) Proceedings, 2020
Orthogonal Convolutional Neural NetworksIn Conference on Computer Vision and Pattern Recognition (CVPR) Proceedings, 2020Deep convolutional neural networks are hindered by training instability and feature redundancy towards further performance improvement. A promising solution is to impose orthogonality on convolutional filters. We develop an efficient approach to impose filter orthogonality on a convolutional layer based on the doubly block-Toeplitz matrix representation of the convolutional kernel instead of using the common kernel orthogonality approach, which we show is only necessary but not sufficient for ensuring orthogonal convolutions. Our proposed orthogonal convolution requires no additional parameters and little computational overhead. This method consistently outperforms the kernel orthogonality alternative on a wide range of tasks such as image classification and inpainting under supervised, semi-supervised and unsupervised settings. Further, it learns more diverse and expressive features with better training stability, robustness, and generalization.

2019
- CVPR
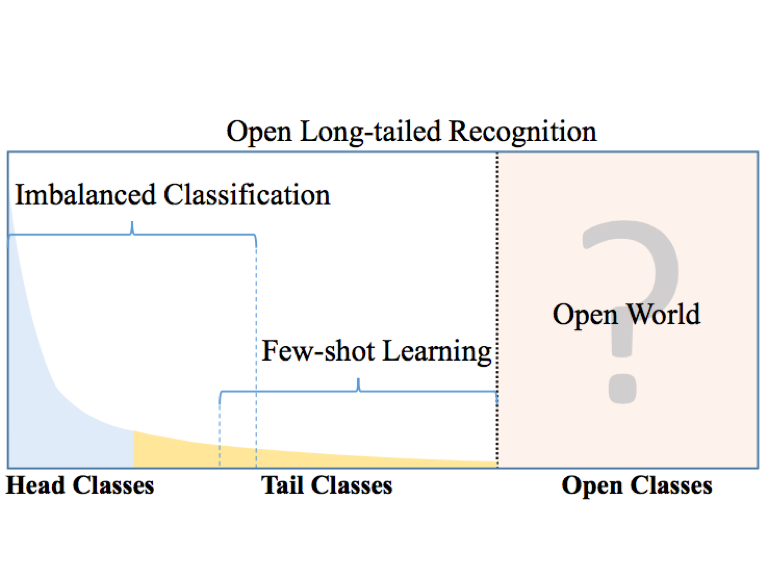 Large-Scale Long-Tailed Recognition in an Open WorldIn Conference on Computer Vision and Pattern Recognition (CVPR) Proceedings, 2019
Large-Scale Long-Tailed Recognition in an Open WorldIn Conference on Computer Vision and Pattern Recognition (CVPR) Proceedings, 2019The paper was selected as an oral presentation (2.5%).
Real world data often have a long-tailed and open-ended distribution. A practical recognition system must classify among majority and minority classes, generalize from a few known instances, and acknowledge novelty upon a never seen instance. We define Open Long-Tailed Recognition (OLTR) as learning from such naturally distributed data and optimizing the classification accuracy over a balanced test set which include head, tail, and open classes. OLTR must handle imbalanced classification, few-shot learning, and open-set recognition in one integrated algorithm, whereas existing classification approaches focus only on one aspect and deliver poorly over the entire class spectrum. The key challenges are how to share visual knowledge between head and tail classes and how to reduce confusion between tail and open classes. We develop an integrated OLTR algorithm that maps an image to a feature space such that visual concepts can easily relate to each other based on a learned metric that respects the closed-world classification while acknowledging the novelty of the open world.
- PBVS @ CVPR
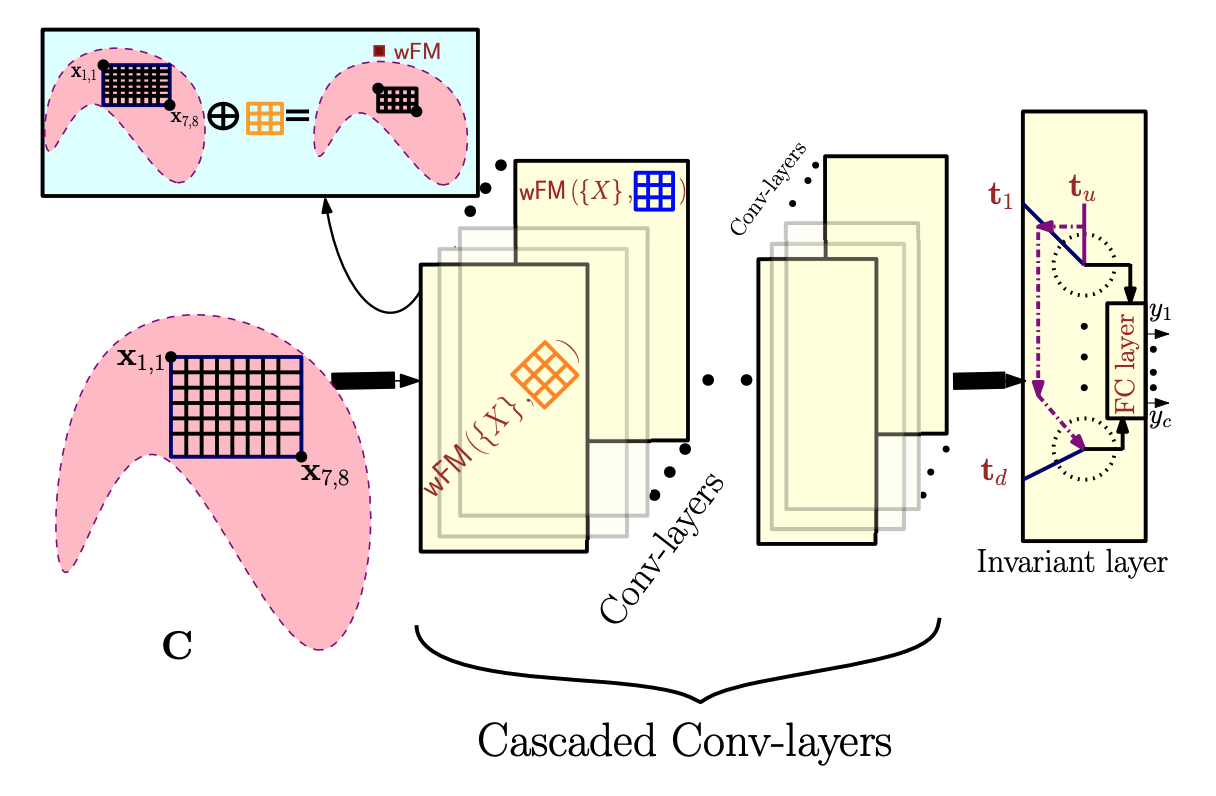 Sur-Real: Frechet Mean and Distance Transform for Complex-Valued Deep LearningRudrasis Chakraborty , Jiayun Wang, and Stella YuIn Conference on Computer Vision and Pattern Recognition (CVPR) Workshop Proceedings, 2019
Sur-Real: Frechet Mean and Distance Transform for Complex-Valued Deep LearningRudrasis Chakraborty , Jiayun Wang, and Stella YuIn Conference on Computer Vision and Pattern Recognition (CVPR) Workshop Proceedings, 2019The paper won the best paper award at 2019 CVPR workshop.
We develop a novel deep learning architecture for naturally complex valued data, which are often subject to complex scaling ambiguity. We treat each sample as a field in the space of complex numbers. With the polar form of a complex number, the general group that acts on this space is the product of planar rotation and non-zero scaling. This perspective allows us to develop not only a novel convoluation operator using weighted Fréchet mean (wFM) on a Riemannian manifold, but also to a novel fully connected layer operator using the distance to the wFM, with natural equivariant properties to non-zero scaling and planar rotations for the former and invariance properites for the latter. We demonstrate our method on widely used SAR dataset MSTAR and RadioML dataset.
- Nature Portfolio
 Insights and Approaches Using Deep Learning to Classify WildlifeZhongqi Miao , Kaitlyn M Gaynor , Jiayun Wang, Ziwei Liu, Oliver Muellerklein, Mohammad Sadegh Norouzzadeh, and 5 more authorsNature Scientific Reports, 2019
Insights and Approaches Using Deep Learning to Classify WildlifeZhongqi Miao , Kaitlyn M Gaynor , Jiayun Wang, Ziwei Liu, Oliver Muellerklein, Mohammad Sadegh Norouzzadeh, and 5 more authorsNature Scientific Reports, 2019The implementation of intelligent software to identify and classify objects and individuals in visual fields is a technology of growing importance to operatives in many fields, including wildlife conservation and management. This study applies advanced software to classify wildlife species using camera-trap data. We trained a convolutional neural network (CNN) to classify 20 African species with 87.5% accuracy from 111,467 images. Gradient-weighted class activation mapping (Grad-CAM) revealed key features, and mutual information methods identified neurons responding strongly to specific species, exposing dataset biases. Hierarchical clustering produced a visual similarity dendrogram, and we evaluated the model’s ability to recognize known and unfamiliar species from images outside the training set.
- TVST
 A Deep Learning Approach for Meibomian Gland Atrophy Evaluation in Meibography ImagesTranslational Vision Science & Technology, 2019
A Deep Learning Approach for Meibomian Gland Atrophy Evaluation in Meibography ImagesTranslational Vision Science & Technology, 2019Purpose: To develop a deep learning approach to digitally segmenting meibomian gland atrophy area and computing percent atrophy in meibography images. Methods: A total of 706 meibography images with corresponding meiboscores were collected and annotated for each one with eyelid and atrophy regions. The dataset was then divided into the development and evaluation sets. The development set was used to train and tune the deep learning model, while the evaluation set was used to evaluate the performance of the model. Conclusions: The proposed deep learning approach can automatically segment the total eyelid and meibomian gland atrophy regions, as well as compute percent atrophy with high accuracy and consistency. This provides quantitative information of the gland atrophy severity based on meibography images.



2018
- PR
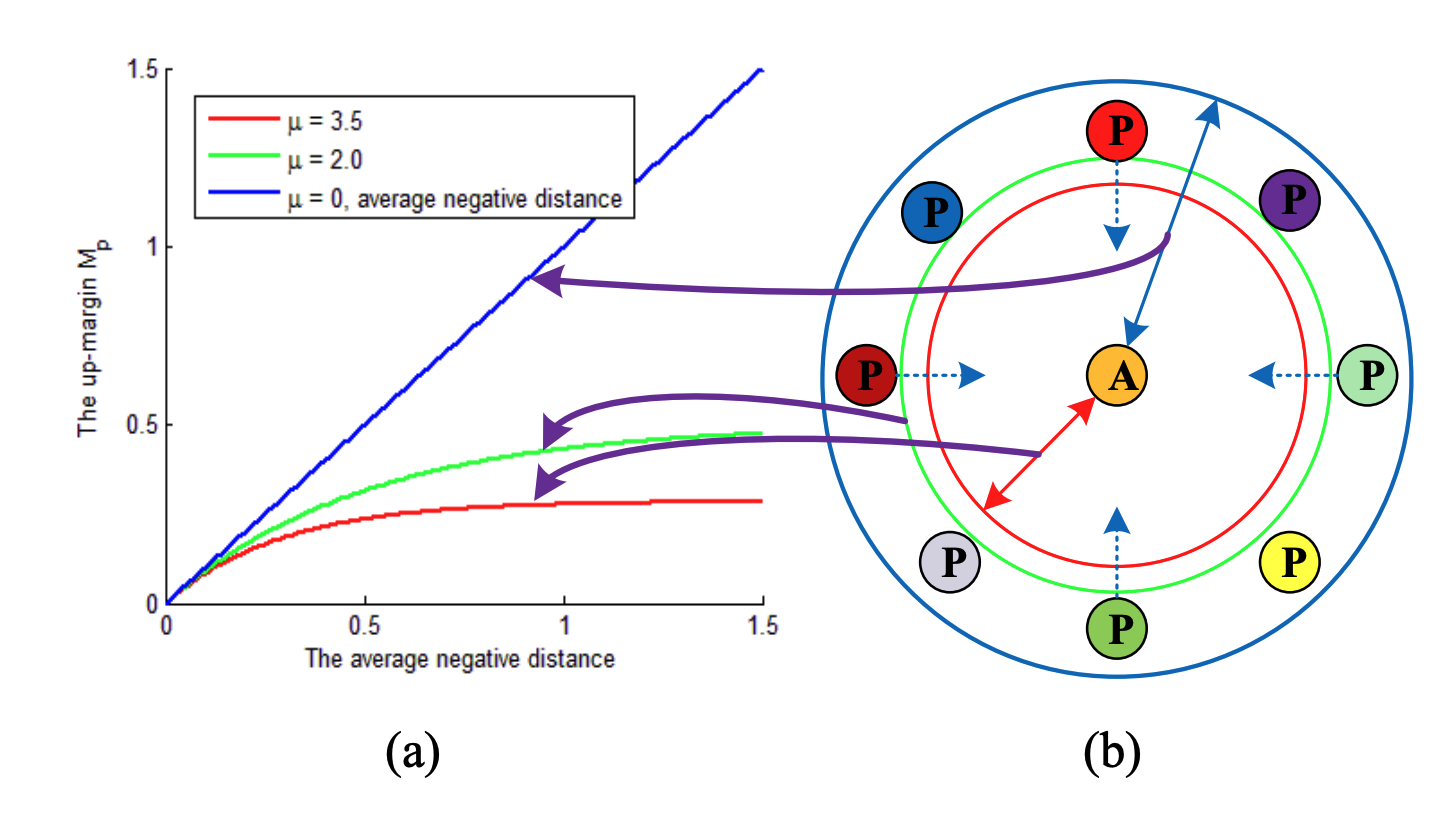 Deep Ranking Model by Large Adaptive Margin Learning for Person Re-IdentificationJiayun Wang, Sanping Zhou , Jinjun Wang, and Qiqi HouPattern Recognition, 2018
Deep Ranking Model by Large Adaptive Margin Learning for Person Re-IdentificationJiayun Wang, Sanping Zhou , Jinjun Wang, and Qiqi HouPattern Recognition, 2018Person re-identification aims to match images of the same person across disjoint camera views, which is a challenging problem in video surveillance. The major challenge of this task lies in how to preserve the similarity of the same person against large variations caused by complex backgrounds, mutual occlusions and different illuminations, while discriminating the different individuals. In this paper, we present a novel deep ranking model with feature learning and fusion by learning a large adaptive margin between the intra-class distance and inter-class distance to solve the person re-identification problem. Specifically, we organize the training images into a batch of pairwise samples. Treating these pairwise samples as inputs, we build a novel part-based deep convolutional neural network (CNN) to learn the layered feature representations by preserving a large adaptive margin. As a result, the final learned model can effectively find out the matched target to the anchor image among a number of candidates in the gallery image set by learning discriminative and stable feature representations. Overcoming the weaknesses of conventional fixed-margin loss functions, our adaptive margin loss function is more appropriate for the dynamic feature space.

2017
- CVPR
 Point to Set Similarity Based Deep Feature Learning for Person Re-IdentificationSanping Zhou , Jinjun Wang , Jiayun Wang , Yihong Gong, and Nanning ZhengIn Conference on Computer Vision and Pattern Recognition (CVPR) Proceedings, 2017
Point to Set Similarity Based Deep Feature Learning for Person Re-IdentificationSanping Zhou , Jinjun Wang , Jiayun Wang , Yihong Gong, and Nanning ZhengIn Conference on Computer Vision and Pattern Recognition (CVPR) Proceedings, 2017Person re-identification (Re-ID) remains a challenging problem due to significant appearance changes caused by variations in view angle, background clutter, illumination condition and mutual occlusion. To address these issues, conventional methods usually focus on proposing robust feature representation or learning metric transformation based on pairwise similarity, using Fisher-type criterion. The recent development in deep learning based approaches address the two processes in a joint fashion and have achieved promising progress. One of the key issues for deep learning based person Re-ID is the selection of proper similarity comparison criteria, and the performance of learned features using existing criterion based on pairwise similarity is still limited, because only Point to Point (P2P) distances are mostly considered. In this paper, we present a novel person Re-ID method based on Point to Set similarity comparison. The Point to Set (P2S) metric can jointly minimize the intra-class distance and maximize the interclass distance, while back-propagating the gradient to optimize parameters of the deep model.
- arXiv
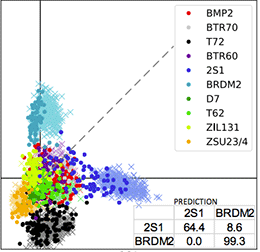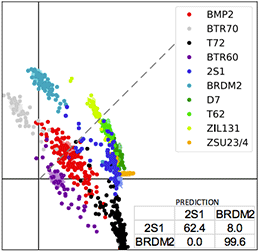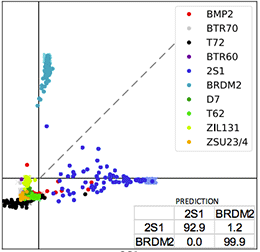 Successive Embedding and Classification loss for Aerial Image ClassificationJiayun Wang, Patrick Virtue, and Stella YuarXiv preprint arXiv:1712.01511, 2017
Successive Embedding and Classification loss for Aerial Image ClassificationJiayun Wang, Patrick Virtue, and Stella YuarXiv preprint arXiv:1712.01511, 2017Deep neural networks can be effective means to automatically classify aerial images but is easy to overfit to the training data. It is critical for trained neural networks to be robust to variations that exist between training and test environments. To address the overfitting problem in aerial image classification, we consider the neural network as successive transformations of an input image into embedded feature representations and ultimately into a semantic class label, and train neural networks to optimize image representations in the embedded space in addition to optimizing the final classification score. We demonstrate that networks trained with this dual embedding and classification loss outperform networks with classification loss only. We also find that moving the embedding loss from commonly-used feature space to the classifier space, which is the space just before softmax nonlinearization, leads to the best classification performance for aerial images. Visualizations of the network’s embedded representations reveal that the embedding loss encourages greater separation between target class clusters for both training and testing partitions of two aerial image classification benchmark datasets.

